| �@ | �@ | ||||||||||||||||||
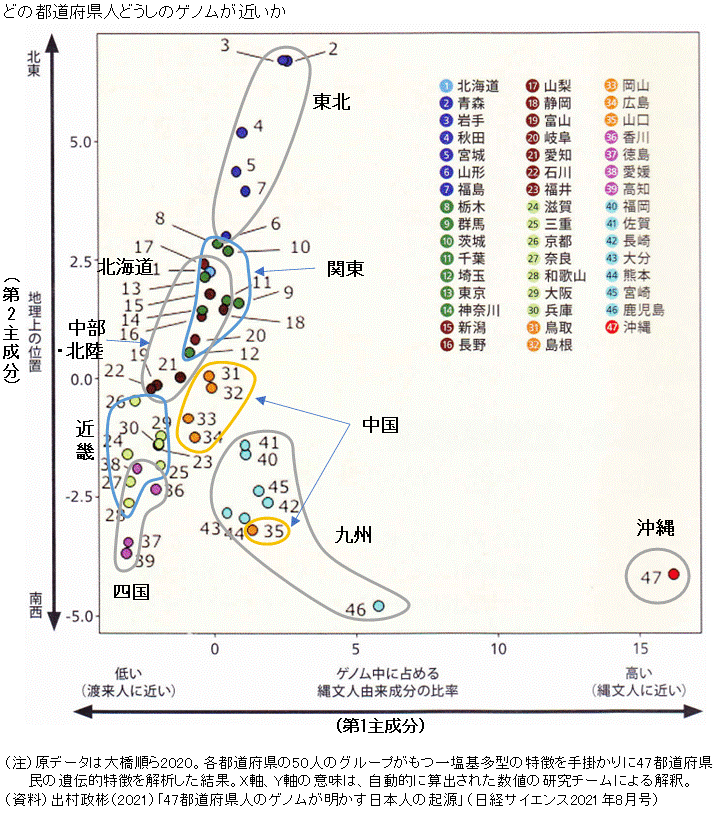
�@����܂ł͋Z�p�I�Ȑ����������T���v���Ɋ܂܂�邷�ׂĂ�DNA�������ɉ�ǂ���Z�p��������V�[�P���T�̎��p���ʼn\�ƂȂ����B���Ɏc���ꂽDNA�̕��͂��i��ł��邪�A�����ł͌��݂̓s���{������DNA����ǂ��A�������݂̗ގ���������𖾂炩�ɂ������͌��ʂ��Љ�悤�B �@���l���̈�`�����r����ꍇ�A�Q�m���̒��ɂ���u�ꉖ��^�iSNP�j�v�ƌĂ�镔�ʂ̈Ⴂ���d�v�ɂȂ�B�q�g�̑S�Q�m���ɂ�32�������̕�����i����z��j������ł��邪�A99.9���͑S�l�ނŋ��ʂł���B�Ⴂ������͎̂c���0.1���ŁA���̑������ꉖ��^����߂Ă���B�ꉖ��^�̕��ʂł́A9����A�Ȃ̂�1����G�Ƃ����悤��1�����������قȂ��Ă���B�Q�m���S�̂̐��S�������ɎU����đ��݂���ꉖ��^�����X�g�A�b�v���ĕ�����̈Ⴂ���ׂ�A�ǂ̃q�g�ǂ�������`�I�ɋ߂��O���[�v�ɑ����邩�������Ă���B������w�̑勴��������͒j���ɋ��ʂ������F�̃Q�m���̒��ɂ���18��3708�����̈ꉖ��^��p���ēs���{�����̈�`�q�p�^�[������͂����i���j�B �i���j���̋L�q�͐}�^�̎������ɋL�ڂ������o�T�C�G���X�̋L���ɂ��B�Ȃ��A������w�̃z�[���y�[�W�ł͓������̊T�v���ȉ��̂悤�ɏЉ��Ă���i�n���T��E��F�^���q�E�勴���u�s���{�����x���ł݂����{�l�̈�`�I�W�c�\���v�A2020/10/14�j�B �@���t�[������Ђ�����Q�m����̓T�[�r�XHealthData Lab�̌ڋq11,069����138,688�����̏���F��SNP�i�@�j��`�q�^�f�[ �^��p���āA���{�l�̈�`�I�W�c�\���ׂ��B�܂��A�̃��x���Ŏ听�����́i�A�j���s���A�����l�i��ɉ��ꌧ�j�Ɩ{�y�l�i��ɉ��ꌧ�ȊO��46�s���{���j����`�I�ɖ��Ăɕ�����邱�Ƃ��m�F�����B�Ȃ��A�{�����ɗp�����f�[�^�ɂ̓A �C�k�l�͊܂܂�Ă��Ȃ��ƍl������B �@ �P����^�iSNP�j�F�q�g��DNA�̉���z��iA/T/G/C��4��ނ̉���ɂ����сj���r�����0.1�����x�̈Ⴂ������B����z��̈Ⴂ�𑽌^ �Ƃ����A1�̉���̈Ⴂ�ɂ�鑽�^��P����^�isingle nucleotide polymorphism; SNP�j�Ƃ�ԁB �A �听�����́F�����̕ϐ��i�������f�[�^�j����S�̂̂�����悭�\�����Ɍ݂��ɒ��s����ϐ��i�听���j���������鑽�ϗʉ�͎�@�� ��B�听�����͂ɂ���Ď������팸���邱�ƂŁA�f�[�^�_���������邱�Ƃ��ł���B�{�����ł́A�̒P�ʂ̉�͂ł͈�`�q�^���A�s���{���P�ʂł̉�͂ł̓A�����p�x��ϐ��Ƃ��ėp�����B �@�`���̐}�́A���̌����̒��ōs�����听�����͂̌��ʂʏ�Ɏ��������̂ł���B �@�\�t�g�E�G�A�����v�I�Ɍ��o������1�听���Ƒ�2�听�����w���AY���ɓW�J���Ă��邪�A�����҂Ɉς˂�ꂽ���߂Ƃ��ẮA�}�ɋL�ڂ��ꂽ�ʂ�A��1�听���́A�ꕶ�l�ɋ߂����n���l�ɋ߂����Ƃ��������ł���A��2�听���͒n���I�ȋ߂��̓����ł���B �@��2�听���́A��1�听���ȊO�̊e�s���{�����̈�`�I�ȗގ����ł���A���݂̒ʍ����x�ɂ����̂ƍl������B�����āA���{����k�ɒ����ł���Ƃ������������2�听���͓�k�����̒n���I�Ȉʒu�Ɖ��߂ł���z�u�ƂȂ����i���{���l�p����������������e�n�͓��S�~�I�ɕ���������Ȃ��j�B �@�S�̂̃��C�A�E�g�́A����Ƌ�B�������ƁA�E�オ��̌X������ɓs���{���������z���Ă��邱�Ƃ����Ăł���B���Ȃ킿�A���{����k�����ɂ���Ɠꕶ�l�I�ȗv�f����܂�A�n���l�I�ȗv�f�����܂��Ă����X���ɂ���B�����ċ�B�͉E������̌X���ɓ]���A����͂���ɉE�����ɃV�t�g���A�ꕶ�l�I�ȗv�f����C�ɋ��܂�B �@��1�听���ɂ��n�敪�z��}������ƈȉ��̒ʂ�ł���B�ߋE�A�l���A�k���œn���l�I�ȗv�f�������Ƃ��������Ƃ�����������B�퐶����ɍŏ��ɓn���l���㗤�����ƍl�����Ă����B�k���n��͎v�����قǓn���l�I�v�f���Z���Ȃ��B�ߋE�A�l���A�k���́A�Õ�����ȍ~�A���a��O���Ɏ���܂Ŏ����I�ɊC�O�ږ������ꂽ�̂ŁA�n���l�I�v�f�������Ȃ����̂�������Ȃ��B  �@�����A�����̒n��敪�����͗]�蓖�Ă͂܂�Ȃ����Ƃ����炩�ƂȂ�B���͖k�O�D�o�ό��̉e���̑傫�����咣���Ă��邪�A���҂����悤�ȓ��{�C���̌��̒n��u���b�N���z�����ߐe���͔F�߂��Ȃ��悤���B�����Ƃ��A�����{�̓ꕶ�x�������m���ɔZ���_�A�܂����k�ɂ�����R�`�̖k���Ƃ̋߂��A���邢�͖k���ƋߋE�̈�`�I�ȋ߂��͓��{�C���n��̑��𗬂̐[��������킵�Ă���Ƃ������悤�B    �@���ɁA�e�n���u���b�N�ɂ���������������B�ӊO�Ȃ͕̂������R�`�̕����֓��ɋ߂��_�A��ʂ��֓���蒆�����ɋ߂��_�A�l���̒��ň��Q�����ɍł��߂��_�A�R���͒����Ƃ�������B�ł���_�Ȃǂł���B
�i2022�N7��30�����^�A8��2�����k�̋L�q�������A2025�N3��23���ꕶ�l�A�퐶�l�̕����摜�j
�m �{�}�^�Ɗ֘A����R���e���c �n |
|
||||||||||||||||||
�@
