ピューリサーチセンターの”When Online Content Disappears”と題された
記事(MAY 17, 2024) ではインターネット上のウェッブ等のオンラインコンテンツが年々消失している状況を紹介している。
当該記事では次のような点が指摘されている。
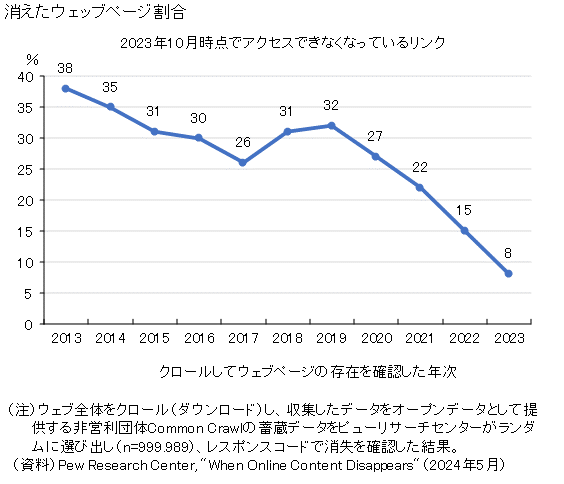
- 2013年から2023年の間に一時期存在したWebページの4分の1が、2023年10月現在アクセスできなくなっている。該当ページが削除されたか、ウェブサイトごと消滅したためである。
- 古いコンテンツに関してその傾向が顕著で、2013年に存在したWebページの38%が現在(2023年10月時点)利用できなっており、2023年に存在していたWebページでもすでに8%が利用できなくなっている(上図)。
クロールしてウェブページの存在を確認した年次別の消失率の推移を見ると、コロナ以前である2019年以前と以後で消失率に段差があるようだ。非常の多くのウェーブページがコロナ影響下のネットブースト期に整理されて失われたかの如くである。
その他、関連して以下のような状況も紹介されている。
- ニュース系Webページの約23%が、政府系WebサイトのWebページでは約21%が少なくとも1つのリンク切れを含んでいる。地方政府のWebページ(市政府のもの)では、リンク切れがより多く見られる。
- WikipediaのWebページの54%には、「参考文献」のセクションにもはや存在しないページを指すリンクが少なくとも1つ含まれている。
- ツイートのほぼ5件に1件が投稿から数カ月後に非公開になっている。これらのケースの60%は最初にツイートしたアカウントが非公開または停止、もしくは完全に削除されたことによるもの。残りの40%はアカウント所有者が個別のツイートを削除したもので、アカウント自体は残っている。
こうした状況に対して、単に刹那的な情報発信が増えていると捉えるだけでなく、人々がオープンな情報共有に無関心になってきているからではないかという心配をする向きもある。ピューリサーチセンターンの記事を紹介しながら八田真行氏はヤフーニュース記事(2024.5.25)で次のように述べている。
「かつて情報は希少だったので、情報への「飢え」のようなものが広く共有されていて、情報はできるだけオープンに、誰でも再利用可能なようにするのが美徳とされていた。ティム・バーナーズ・リー肝いりのContract for the Webにもあるように、ワールド・ワイド・ウェブは「知識を自由に利用可能とするように」作られたのである。それが今では、少なくとも人間には過剰なほどの量の情報が氾濫しているので、相対的にそこまで情報共有に熱心ではなくなりつつあるということなのかもしれない。だとしたらワールド・ワイド・ウェブがあまりに成功したためにそうなったわけで、皮肉なこととも言えるだろう」。
さらに、こうした状況から、AIの発達にも限界が生じると予想されている。チャットGPTのような大規模言語モデル(LLM)の開発には、膨大な学習データが必要だが、主な収集先はネットである。しかし、使えそうなネット上のデータは徐々に使い尽くされ、良質なデータは2026年には底をつくと見られている。いわゆる「AIの学習データが底をつく」"2026年問題"である(
ヤフーニュース記事、2023/7/24)。